
You hit a URL and Drupal gives you a page back. Magic! But perhaps you are wondering, what is Drupal doing under the hood? You know that putting it down to magic is not going to help you to create your own custom modules.
Drupal can be a complicated beast. So at this stage, I am not going to go into every little detail. Instead, we will take a look at a simple example to illustrate the main stages in the process.
Why is this important to understand?
Possessing a high level understanding of how Drupal responds to a request for a page is critical to understanding the bigger picture.
Firstly, when you create a Drupal module, you need to leverage the rest of Drupal. Modules are not standalone programs - they are a piece of the Drupal puzzle and Drupal will do a lot of work for you. But you need to understand what Drupal is doing first to be able to hook into it.
Secondly, when you create a module, something will probably go wrong. At least one piece of code won’t work as expected. Ahh.. a bug! When you debug code in a module, you need to know what the rest of Drupal is doing during the request lifecycle. It could be another module (or core) interacting with your module in an unexpected way that is causing the bug.
Thirdly, security. Drupal has a lot of security handling built in. Just like leveraging the power of Drupal for functionality, you need to leverage the security features of Drupal. Understanding the whole process will help you do just that.
Simple Example
This example is a simple blog page: http://befused.com/drupal/munich. This is a standard node page which is created using node/add/article. For the sake of simplicity, I have ignored caching. I will discuss how caching affects some of these steps in a future post.

Drupal answers a series of questions to figure out what to do. Let’s go through each of the main questions, one by one.
What do I do with the URL?
Initially, the web server receives the full URL - http://befused.com/drupal/munich. But Drupal only cares about the internal path, so it separates it from the domain name. This actually happens before it even reaches Drupal in the .htaccess file (.htaccess is an Apache configuration file that allows developers to override web server settings).

How do I get started?
Drupal then calls index.php, which lives in the root of a Drupal install. Everything happens via index.php. To get started, Drupal runs though a bootstrap process, which initialises the database, sets sessions, loads libraries and so on.

What is the path actually an alias?
Remember, Drupal has already separated the path from the domain? But drupal/munich is actually an alias and not the real Drupal internal path. The Drupal internal path is node/262. drupal/munich is mapped to node/262 in the database.

Which module is responsible for the content?
The menu system maps the internal path to a call back function, which is normally responsible for getting content from the database. A lot of the business logic happens at this point.
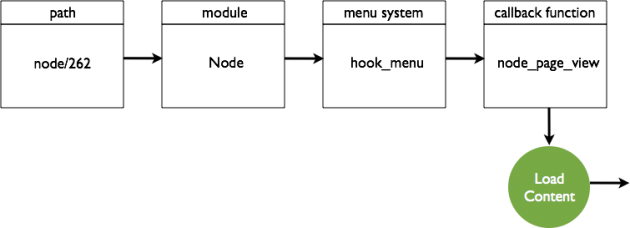
Do other modules want to extend or alter?
Hooks fire, allowing other modules to hook into the process at various points. These modules can change the content returned, add business logic and extra functionality.
An example of this is adding comments to the blog post. The Node module provides a hook in point for other modules. The Comment module utilises this and attaches comments to nodes. This is where the true power of Drupal is, because modules can provide any number of hooks for other modules to implement.

There could be hundreds of hooks implemented in modules, all able to alter the content.
How should the page look?
Theme system styles the content and the page for the browser. The theme system itself can call more hooks and change the content. The theme system is more than just the theme itself. It includes theme functions and templates at module level as well.

Drupal has answered all the questions, and is ready to return a fully formed HTML page to the browser, along with CSS and Javascript. The browser then renders the page for the user to consume.

Summary
This was a high level explanation of how Drupal deals with a page request. There is a lot of detail at each stage, but it is important for you to understand the overall picture.
To summarise the process:
You request a page.
In turn, Drupal:
- Separates the internal path from the full URL
- Bootstraps and initialises the database, sessions etc
- Maps the path to a callback function, which gets the primary content
- Modules can hook into the process and extend functionality and alter the content
- The Theme System generates the HTML and styles it.
- Drupal returns a fully formed HTML page to the browser
- The browser renders the HTML page for the user
My book, Master Drupal 7 Module Development, will dive deeper into this. In particular, writing custom modules that define paths and callbacks, and implementing and defining hooks.
Take a look at the attached PDF which illustrates the request lifecycle.
If you like this post, you would enjoy my weekly Drupal newsletter, where I send out tutorials on starting and getting better at Drupal development. You can sign up in the box below, where you will receive a free 7 day Starting Drupal Dev course, followed on with the weekly newsletter.
To scale the Drupal development learning curve faster, check out my book Master Drupal Development. It will help you master module development faster to become a fully fledged Drupal developer.

{kind=link}